Downloading Data From the Synapse UI
Remember, when downloading this way, the maximum size of a download is 5 GB, or a maximum of 100 files if using the download cart.
Once you have found and gained access to your data of interest, here’s how to download that data. Reference the screenshots below for a visual representation of the instructions.
Within the project, you may see a series of folders. Any standalone files are downloadable using the down arrow icon in the Download column for that file (1). You can click the > arrow next to any folder to expand it and view its files within (2). To download any individual file from here, click the download icon in the Download column for that file (1), which will add that file to your download cart.

Alternatively, if you want to download every file within a folder, you can do so more efficiently. Click on the name of the folder (instead of just expanding it). On this new page with just that folder and its contents, click Download Options (3) followed by Add to Download Cart (4). You’ll be notified of the number and size of files, and asked if you wish to proceed—click Add (5).

Repeat this process for as many files (individual and within folders) that you want to download!
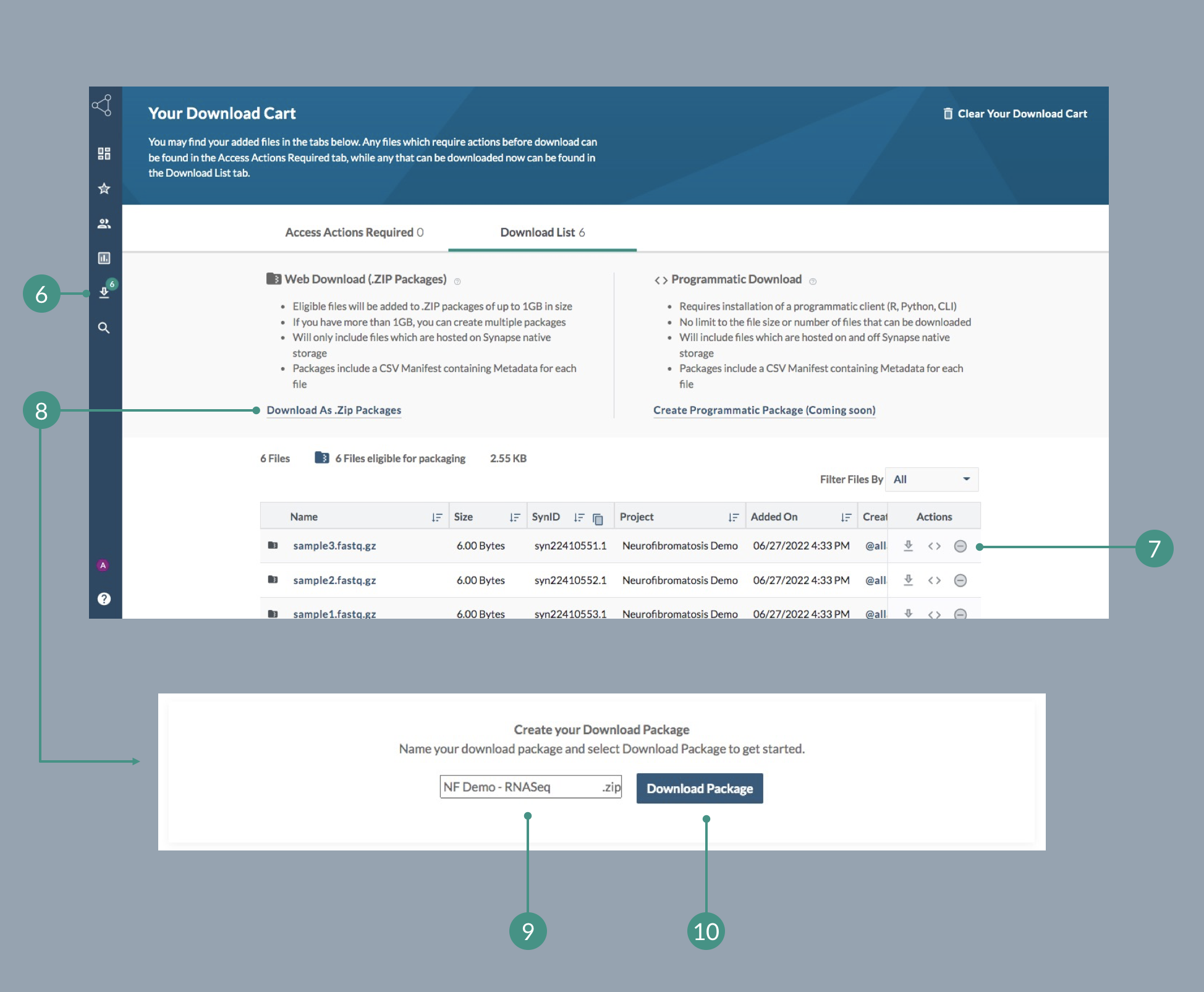
As you add items to your download cart, notice that this gets reflected in the Downloads icon of your Synapse toolbar on the left (6). Click this icon once you are ready to download all files in your cart (at this point, they are not downloaded to your computer yet).
In your download cart, review all the items in the list. From here, you can use the Action column to remove any files that you no longer wish to download (7).
When you’re ready to download, click Download As .Zip Packages (8). This will reveal a Create Your Download Package box below, which will prompt you to enter a package name (9). Enter a name that will be easy to find and follows protocols for your project. Then, click Download Package (10). The zipped package will now be available on your computer.